| Authors | Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, Rong Jin |
| Title | FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting |
| Publication | Proceedings of the 39th International Conference on Machine Learning (ICML 2022) |
| Volume | 162 |
| Issue | x |
| Pages | 27268-27286 |
| Year | 2022 |
| DOI | x |
Introduction
Background
- Long-term time series forecasting is a long-standing challenge in various applications (e.g., energy, weather, traffic, economics).
Previous Research
- Despite the impressive results achieved by RNN (Recurrent Neural Network)-type methods, they often suffer from the problem of gradient vanishing or exploding, significantly limiting their performance.
- Transformer has been introduced to capture long-term dependencies in time series forecasting and shows promising results.
- Numerous studies are devoted to reducing the computational cost of Transformer, as high computational complexity and memory requirement make it difficult for Transformer to be applied to long sequence modeling.
Proposed Model
- Frequency Enhanced Decomposition Transformer, or FEDformer, for long-term time series forecasting is proposed.
- The model incorporates a seasonal-trend decomposition approach and Fourier analysis with Transformer to better capture global properties of time series.
- The proposed model achieves linear computational complexity and memory cost by randomly selecting a fixed number of Fourier components.
Significance
- The proposed model improves the performance of state-of-the-art methods by 14.8% and 22.6% for multivariate forecasting and univariate forecasting, respectively.
- Extensive experiments were conducted over 6 benchmark datasets across multiple domains (energy, traffic, economics, weather and disease).
- The effectiveness of the Fourier component selection method is verified both theoretically and empirically.
Proposed Model

- Long-term time-series forecasting is a sequence to sequence problem
- The input length is denoted as I and output length as O, while D represents the hidden states of the series
- The encoder input is an I × D matrix and the decoder has (I/2 + O) × D input.
- FEDformer Structure consists of deep decomposition architecture, including FEB (Frequency Enhanced Block), FEA (Frequency Enhanced Attention), and the MOEDecomp (Mixture Of Experts Decomposition) block, multilayer structure encoder with seasonal components, and multilayer structure decoder with seasonal and trend components.

- FEB module which has two different versions (FEB-f & FEB-w) that are implemented through DFT (Discrete Fourier Transform) and DWT (Discrete Wavelet Transform) mechanism respectively and can seamlessly replace the self-attention block.

- FEA module that has two different versions (FEA-f & FEA-w) which are implemented through DFT and DWT projection respectively with attention design and can replace the cross-attention block.
- The final prediction is the sum of the two refined decomposed components as WS · X M de + T M de, where WS is to project the deep transformed seasonal component X M de to the target dimension.
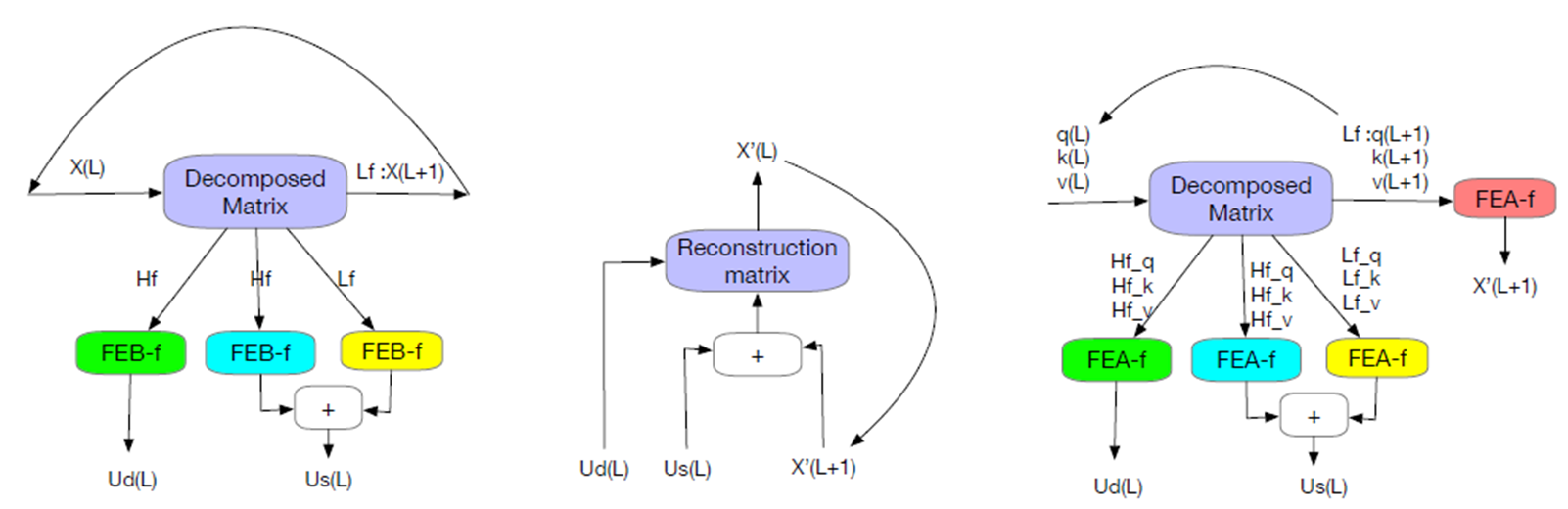
- The Fourier Enhanced Structures use DFT.
- DFT is defined as Xl = PN−1 n=0 xne−iωln, where i is the imaginary unit and Xl, l = 1, 2...L is a sequence of complex numbers in the frequency domain.
- FEA module has two different versions (FEA-f & FEA-w) which are implemented through DFT and DWT projection respectively with attention design and can replace the cross-attention block.
Experiment
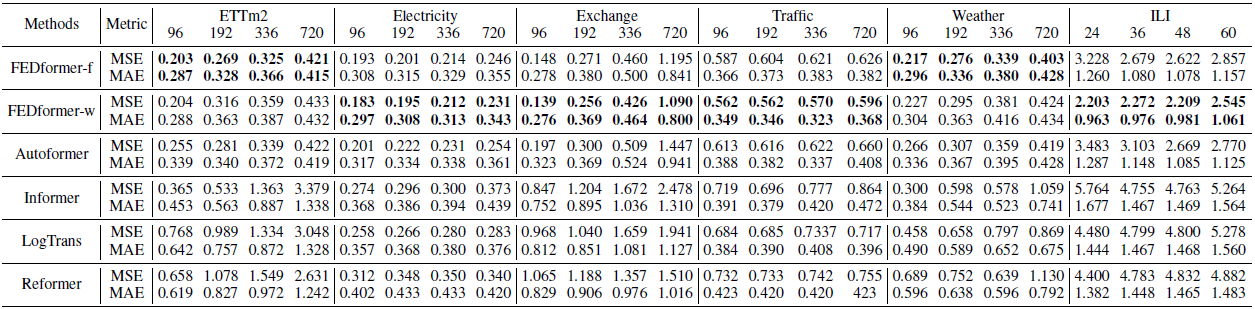
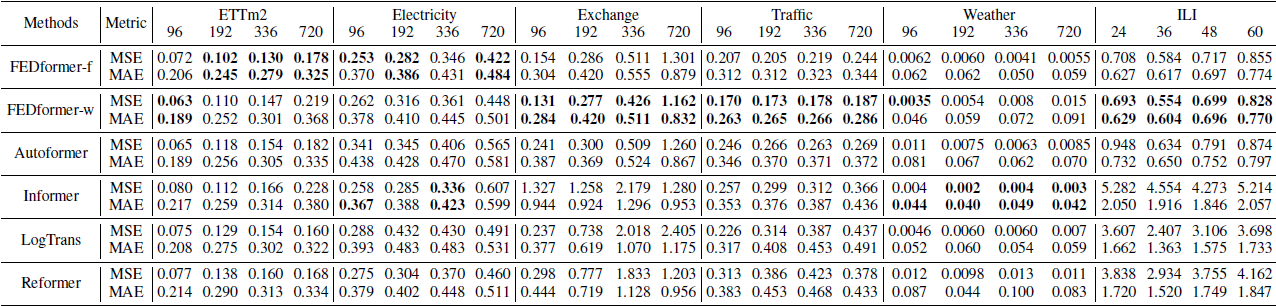
- FEDformer achieves the best performance on all six benchmark datasets for multivariate forecasting and univariate forecasting.
- FEDformer yields an overall 14.8% relative MSE (Mean Squared Error) reduction compared with Autoformer for multivariate forecasting, and an overall 22.6% relative MSE reduction for univariate forecasting.
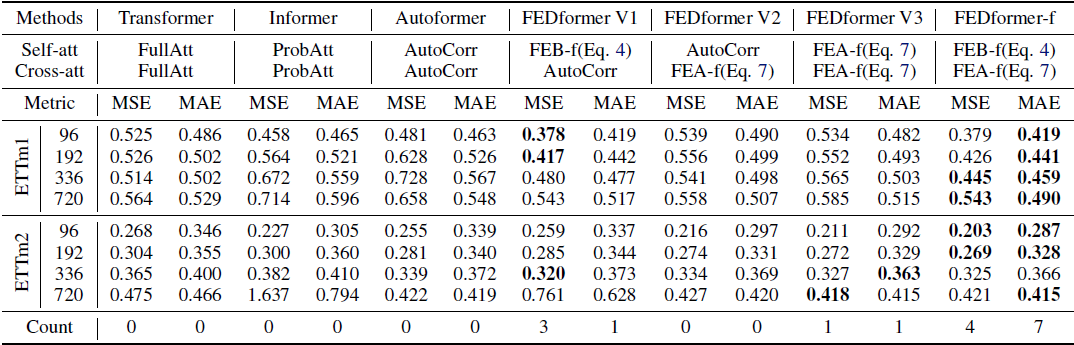
- FEDformer with FEB and FEA blocks improves performance in all 16/16 cases for ablation experiments compared to Autoformer.
- FEDformer uses frequency transform to decompose the sequence into multiple frequency domain modes to extract the feature, which differs from Autoformer's selective approach in sub-sequence selection.

댓글